Feed: AWS Partner Network (APN) Blog.
Author: Balaji Gopalan.
By Nadav Sharir, VP Engineering at Behalf
By Liran Keren, Director of Engineering at Behalf
By Balaji Gopalan, Sr. Solutions Architect at AWS
To be a successful fintech startup, companies have to build solutions fast so the business can achieve its goals. However, you can’t compromise on security, reliability, or support.
Behalf is an AWS Partner Network (APN) Advanced Technology Partner that offers short-term financing with flexible repayment terms to U.S.-based businesses.
As an AWS Financial Services Competency Partner, Behalf is committed to delivering reliable, secure, low-cost payment processing and credit options to business customers.
In this post, we will detail the decision-making process Behalf went through in evaluating cloud solutions for its core platform.
We’ll also outline why the engineering team chose Amazon Managed Streaming for Apache Kafka (Amazon MSK) to meet its increasing streaming data needs in a reliable and cost-efficient manner.
Background
Behalf’s core platform offers loans to small businesses, and its online financing platform works as a line of credit so that organizations only pay interest on the amount of credit they use to fund their purchases.
By paying vendors up front, Behalf eliminates the vendors’ credit risk. Vendors get paid on day one, bringing their days sales outstanding (DSO) to zero, and removing their responsibility for collections.
Behalf’s cloud-based service is available at many points of sale, including e-commerce, managed sales, and invoicing.
The engineering team at Behalf recognized it needed to establish an architecture that would scale with the growing number of merchants, customers, and transactions the company was managing—all while providing the best user experience possible for its business customers.
Technically, this meant Behalf needed to quickly handle increasing demand on its system without compromising on performance and throughput. The team accomplished this by building a distributed architecture based on microservices.
Goals for the project included:
- Scalability: The solution needed to manage an increasing load of transactions while maintaining throughput and performance.
- Resilience: Behalf’s solution needed to be tolerant of failures, and the system needed to be designed to avoid collapsed failure in which surrounding services degrade when a single service is down.
- Consistency: Behalf is a financial services solution, so its data needed to be fully consistent upon action.
Behalf’s architecture is based on microservices, where each service drives a clear business domain such as orders, customers, payments, and risks. Each service has its own bounded context and, therefore, owns its own data model; other services just need access to the data.
The key to Behalf’s architecture is based on the need for autonomy, meaning that each service is independent at runtime from any other service. This calls for asynchronous and event-based communication between the different services. For example, service A produces a business event, while service B reacts to it.
In many modern software design patterns, data plays a vital role in driving architectural decisions. Since Behalf wanted to guarantee the independence of each service, it needed to have the public data of each service be available for other services, with minimum dependency on the availability of the given services.
Since it also needed to assure scalability, resiliency, and data consistency, Behalf’s engineering team had to find a way to make the data both available and current for the services. When a service acted upon an event, the data needed to be up to date.
Behalf also wanted to guarantee each service would be able to evolve its data model without breaking other services via an anti-corruption layer that assured its long-term compatibility. This goal was especially challenging because Behalf wanted to assure a real-time experience for end-users, without any lags.
Data Solution Alternatives
In terms of data, Behalf wanted to allow its internal business intelligence and risk/fraud analysis services to obtain a full copy of the entire distributed data model. To do this, the engineering team identified ways to address this data challenge.
Data Access by Synchronous REST API
REST API would achieve the data consistency Behalf needed, and with an anti-corruption layer that defends the inner data model of a bounded context. With this solution when microservice A, receives a business event E, it can fetch data using REST from another microservice.
Although this solution is simple, it couldn’t work for Behalf because it would have broken runtime autonomy, and eventually would have led to a system where all components are tightly coupled.
Business Events Carrying Entities
The engineering team at Behalf then explored a Domain-Driven-Design (DDD) solution. Upon publishing a business event, the producer side can paste a public model of entities related to that event.
With this solution, Behalf could easily achieve resiliency with true isolation between bounded contexts. However, the data was available to the consumer only when a business event arrived.
What if the data is needed for later use? It can “duplicate” the data, having it persisted into its own data model, which is completely fine. But then, what if microservice A gets an event from microservice B and now it needs data from microservice C?
Exploring these kinds of ideas, Behalf learned it was not practical and many new features would demand changes to many microservices.
In addition, systems like business intelligence (BI) and risk needed access to all the data (current and historic) regardless of the running business flow. Clearly, this approach was not feasible for such systems, as they would have a need to register to all business events and remodel all the public data models into their own data model.
Data Events Stream and Business Events Stream
Behalf concluded it needed to stream a public adaptation of the data models and have it pushed into consumer-side databases. This would achieve isolation and resiliency, and provide access to the public data at any point in time, as needed.
Having more than one stream means there’s no guarantee in data consistency, however. Let’s say microservice producer A publishes a business event and microservice B consumes it. Data that changed in A before publishing of the event may not have arrived to B yet. It could be processing the business event using stale data. Causal ordering is critical.
So, Behalf’s team started to think about how to synchronize between the business events stream and the data events stream. Several ideas cropped up—such as joining the streams on the consumer side—but then they would have to pay with latency caused by the windowing. Windowing is a heuristic approach, and without really knowing the right size of the window, they could lose some data.
Another approach was to have business events carry metadata of versions of the public data model. Consumers would be able to know their data (from other services) is stale and know to wait with the processing of events until the relevant data arrives.
This idea was soon dropped, as well, because of its complexity. Microservice A publishing an event E to microservice B might be related to data from microservice C. To publish the related entities versions, data versioning had to be global and that implies having a centralized component.
The Single Stream
Behalf ultimately concluded a single queue for both data events and business events was needed.
In this case, microservice A would run some business code and make changes to its data, resulting in the publishing of corresponding data events to the stream. When microservice A wants to publish the business event E, it publishes to the same stream. Microservice B consumes the single stream and processes the data events, storing them in its own schema.
When microservice B arrives to deal with event E, all the prior data would have already been processed. With this approach, Behalf achieved all of its design goals of resiliency, isolation, and data consistency. It also delivered a true event-based solution and no dummy latency from windowing.
In Figure 1, you see that when publishers publish data events D1 and D2 and business event E, all events are streamed on the same partition. As a result, consumers consume the events in the same order: D1 > D2 > E.
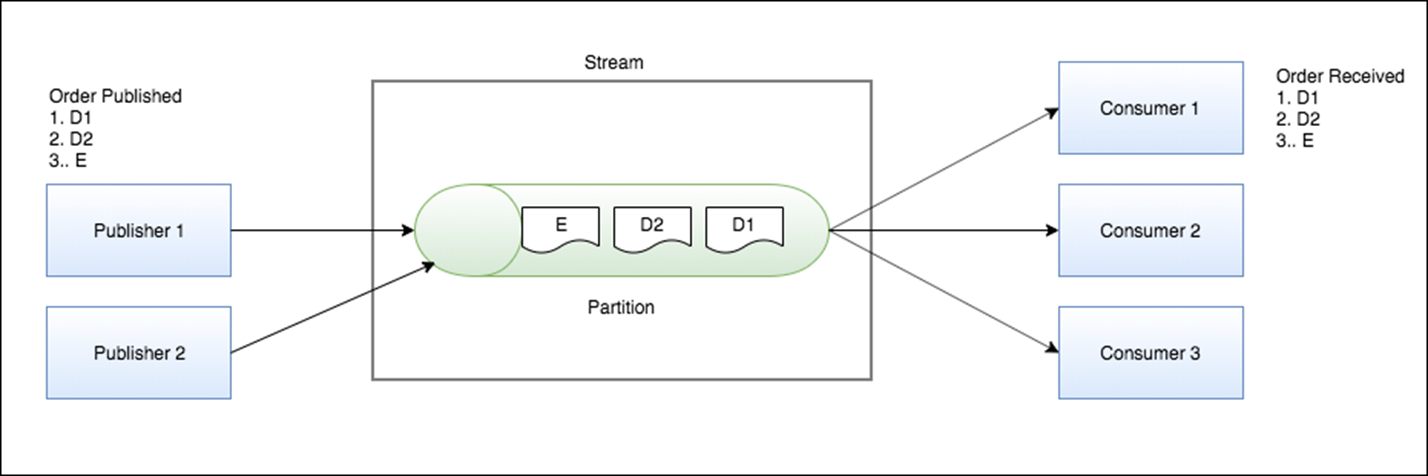
Figure 1 – Streaming data and message ordering.
Solution Architecture
Knowing that Behalf needed a single topic for both data and business events, it faced the problem of maintaining transactionality. During a run of some unit of work, this means that if there are failures both events should not be published.
At first, the engineering team thought of publishing data events from the repository layer, which would guarantee transactionality and ordering in a publishing unit of work. However, what happens with data migrations?
Behalf could make sure any data migration would go through the application data model. But that’s very limiting and would tie its hands from doing any data manipulation directly on the database.
Another way to accomplish this is by streaming change data capture (CDC). Every database has a notion of a transaction log describing all data manipulation events in a manner of event sourcing, for example:
Fetching the account with id “1234” will return the account with the name Jim, since the record was created with the name of John and then updated into Jim. This history exists in the database transaction log and is the core of the replication abilities of databases.
Instead of doing full replication of one database into another, Behalf’s team thought of an ability to “subscribe” to the log and stream all events so that each consumer would be able to deal with the events. This approach guaranteed every change was committed to the database, no matter if it would be streamed out manually or through the application.
But that brought the team right back to square one, where its business events were published without synchronization to the data events.
So, they said, “Why not consider the business events as data events also?” Instead of publishing them directly to the broker, Behalf could create a table named business_events in all microservices. Then, publishing a business event would mean storing a record in that table.
Until now, Behalf’s engineering team used RabbitMQ as the event broker. There was never a problem of scale, as they only published business events and each type was published to its own topic. Now, the team wanted to publish enormous volumes to just one topic and needed to guarantee data retention and high throughput of production and consumption.
Needing a fault-tolerant, durable streaming, and messaging platform, Behalf chose to adopt Kafka, an open-source event broker that also saves the data and can act as an event store.
In addition to Kafka, the engineering team decided to use Kafka Connect, which is an open-source component for Kafka that abstracts connection to data sources like databases, search indexes, or even files, streaming the data through Kafka into targets.
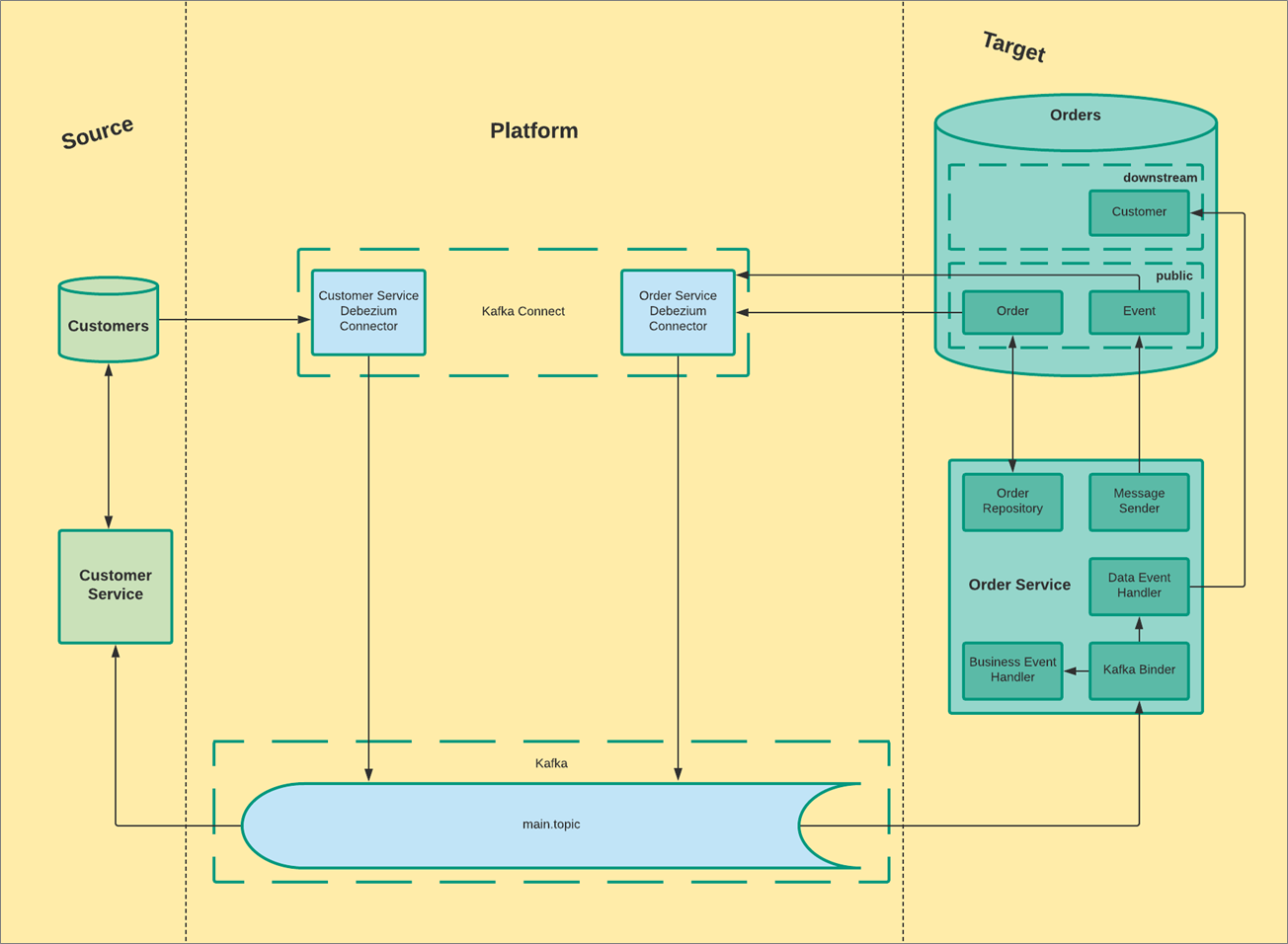
High-Level Layout
Kafka Connect abstraction consists of connectors that are also developed by the open-source community. Debezium is an implementation of such a connector, and it connects to the database replication slot and streams CDC events. Debezium also supports transformation and blacklisting of events that enabled Behalf to achieve an anti-corruption layer to guarantee isolation and loose-coupling.
Kafka can handle massive amounts of streaming data and supports partitioning, meaning that events in the topic can be partitioned by some key. Order within the partition is maintained by using a single listener (thread) per partition. One listener can handle several partitions, but one partition should always be handled by just one thread.
Kafka Connect also consists of source and sink (target). For this solution, Behalf uses only the source (Debezium) and its microservices users to consume directly from Kafka.
The team created an infrastructure layer for the microservices, both for the producer side and the consumer side.
The producer side features an anti-corruption layer and abstraction for sending a business event, which is actually saving it into the database. On the consumer side is a component in the microservices that distinguishes between data events and business events and delegates them to actors in the application layer.
In Figure 2, you see that customer-service (source) writes data to its own database, and Kafka-connect transforms changes into Kafka messages. From there, Kafka transfers data events and business events on the main single topic.
Finally, the order-service core layer (target) consumes the events and pushes customer-service data into downstream.customer (